For the first half of the semester (before midterm), tutorials will aim to provide a solid foundation for machine
learning. Note that calculus and the basics of probability and statistics are not covered here and assumed as
prerequisite, as they are more or less required for almost any undergrad program, and it's not feasible to include
them in this already very packed schedule. Since a foundation in probability and statistics is so essential for
machine learning, here is a
list of lectures that cover the fundamentals, but we won't cover them in this course and it might be a bit
challenging to go through all of them in a short period of time.
For the second half of the
semester, tutorials
will try to cover the breadth of machine learning:
current
topics and frontiers in machine learning.
Tutorials
will be held at Tuesdays 10 am and 10 pm EST so that it'll work for every time zone. You only need to attend
one of the two each week. Following are tutorial contents from last year, you are encouraged to check these
contents since we are going to cover similar topics.
This page will be updated
as the course goes on. Throughout the course, meaningful Q/A's will also be reflected here, we appreciate your
feedback
and gradient to help us continuously improve the course.
Tutorial 1: NumPy review, dataset split, no free lunch, KNN.
Dates: 1/19
[Colab ipynb], [Video]
Materials from last year:
NumPy Review. This
tutorial gives a conceptual and practical introduction to Numpy. The code can be found here.
Dataset split. Kilian Weinberger's Cornell class CS4780 Lecture 3 starts to talk about proper dataset split
at 2:00
until 24:00.
No free lunch. The same lecture touches on no free lunch theorem and algorithm choice starting at 27:10
until 33:30.
K-Nearest-Neigbors. The same lecture starts to talk about KNN at 36:00
until the end. The lecture
note also has an easier to follow convergence proof for 1-NN in the middle of the page and it also has a nice
demo of curse of dimensionality after that.
K-Nearest-Neigbors with Numpy. Prerecorded
video going through the implementation of
K-Nearest-Neigbors using Numpy. Code.
A very nice Probability Cheatsheet share by a
student.
Tutorial 2: Linear Algebra Foundation.
Dates: 1/26
[Video]
Format
This week we will present a set of slides located here (annotated version) during the tutorial time slots.
We also provide links to the classic lectures by Gilbert Strang, which we recommend watching.
The aim is to refresh your
knowledge on linear algebra so that you'll be more comfortable working with matrixes later in the course. If you don't
have enough time, you could consider watching it at 1.5x or 2x speed. If you find the concepts in the topics listed
below hard to comprehend,
you may consider watching the first three lectures of that course. Here are the (optional) lectures: 1, 2, 3.
Eigen decomposition. Video.
Transcript
(The middle tab). We encourage you to watch the whole video.
Positive Definite and Semidefinite Matrices. Video.
Transcript
(The middle tab). He briefly discussed convexity and gradient descent here, you can just take it as a prelude as
we'll
be getting into more details about those topics later.
We encourage you to watch the whole video.
SVD. Video.
Transcript
(The middle tab). I particularly like how he talked about the geometry of SVD starting from 28:50,
even though there's a minor mistake
there too. The mistake is the second step, multiplying the diagonal matrix of singular values. It should stretch
along
the standard basis, not along
the
rotated
basis. In other words, the sigma should be applied on the x-y directions, not the rotated directions, you can refer
to a
correct picture on wikipedia here.
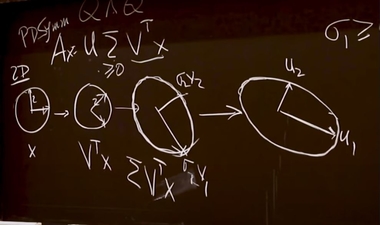
Screenshot from the lecture at 34:06

Geometric interpretation of SVD from wikipedia
I particularly like how he showed you can infer the degrees of freedom for rotation in higher dimensional space that
cannot be
visualized. How cool is
that! For example, how many degrees of freedom you can rotate a starship in a 4 dimentional space? You can find the
answers from this video. Another motivation to watch the whole video is that he had a nice joke at the end. :)
Hopefully after those videos are you will be familiar enough with matrices for the rest of this course. Here is the
great Matrix Cookbook which has a huge
list
of mathematical facts around linear algebra, it's a great reference when you are searching for a particular formula or
idendity. A more compact reference from CSC311 can be found here.
Tutorial 3: Gradient Descent.
Dates: 2/2
This week we will cover basic ideas in gradient descent.
[Colab ipynb],
[slides]
, [Video]
Materials from last year:
First of all let's make sure you have enough background. Convexity was briefly mentioned by Gilbert
Strang in the previous tutorial, here is a more detailed tutorial on the concept of convexity.
I have put what I think is the minimum amount of
calculus that you need to know into this list. If you don't already have a background in multivariable calculus, or if
you learned about it so long ago that you almost
forgot everything, you are encouraged to go through the videos in that list. This
video is particularly useful as it has nice visualizations of contour maps, which are very common in machine learning
and in this course. If
you still have more time, here is the full unit on
derivatives of multivariable functions on the Khan Academy. You could consider watching all the videos at 1.5x
speed.
Here is a list of short videos by Andrew Ng on gradient descent.
Gradient Descent intro, for logistic regression. Video.
Gradient Descent on multiple samples Video.
Vectorization. Video.
Gradient Descent for NN Video.
Backprop intuition Video.
Forward and backward propagation Video.
Gradient checking. Video.
Mini batch gradient descent Video.
Understanding mini batch gradient descent Video.
Implementation of gradient descent: Code.
Tutorial 4:
Dates: 2/9
This week we will cover some of the basics of Jax via the jupyter notebook hosted on colab here.
[ipynb]
We will also look at the basics of Pytorch if time permits via the notebook here.
[ipynb]
Here is a recording of the tutorial [Video].
Mid-term review:
Dates: 2/23
[slides],
[video]
last year:
[Part1 slides][Part1 slides with
solution] [Part2 slides] [Part2 slides with
solution (Corrected)]
Tutorial 6: Convnets.
Dates: 3/2
In this tutorial we will cover some example convnets - [colab], [ipynb].
[Video]
Tutorial 7: RNN, Transformers
Dates: 3/9
[slides],
[colab],
[video]
Hugging Face and tutorial notebooks: here.
The illustrated transformers series: here.
Tutorial 8: Hyperparameter Optimization and Bayesian Optimization
Dates: 3/16
In this tutorial we will cover hyperparameter optimization, focusing on Bayesian optimization, and briefly touch gradient-based hyperparameter optimization.
Also, here is a fun distill article on Bayesian Optimization that you can read separately if interested.
[slides],
[colab],
[ipynb]
[Video]
Tutorial 9: Policy Gradient
Dates: 3/23
In this tutorial we review HW3 and discuss policy gradient method in reinforcement learning.
[slides],
[Video]
Tutorial 10: Final Project Review
Dates: 3/30
In this tutorial we will review the final project.
[slides],
[colab],
[ipynb].
[Video]
Tutorial 11: Self-Supervised Learning and Final Project Prep.
Dates: 3/30
Self-Supervised Learning.
Please watch this lecture from here
to 1:02:00, where the foundational ideas of self supervised learning in vision are covered.
Final project. Slides

